

Unity ML Agents & Reinforcement Learning

In honor of the ongoing World Cup, I worked this week on training agents to play soccer as a team. I used the Unity Game Engine and based the scene off of a demo scene in their ML Agent library.
Unity Setup
Unity launched ML Agent last September, and the documentation is now quite good. Visit this guide for information on setting everything up. If you already have Tensorflow and Unity set up, it’s simply a matter of downloading ML Agents from github and opening unity-environment as a new project.
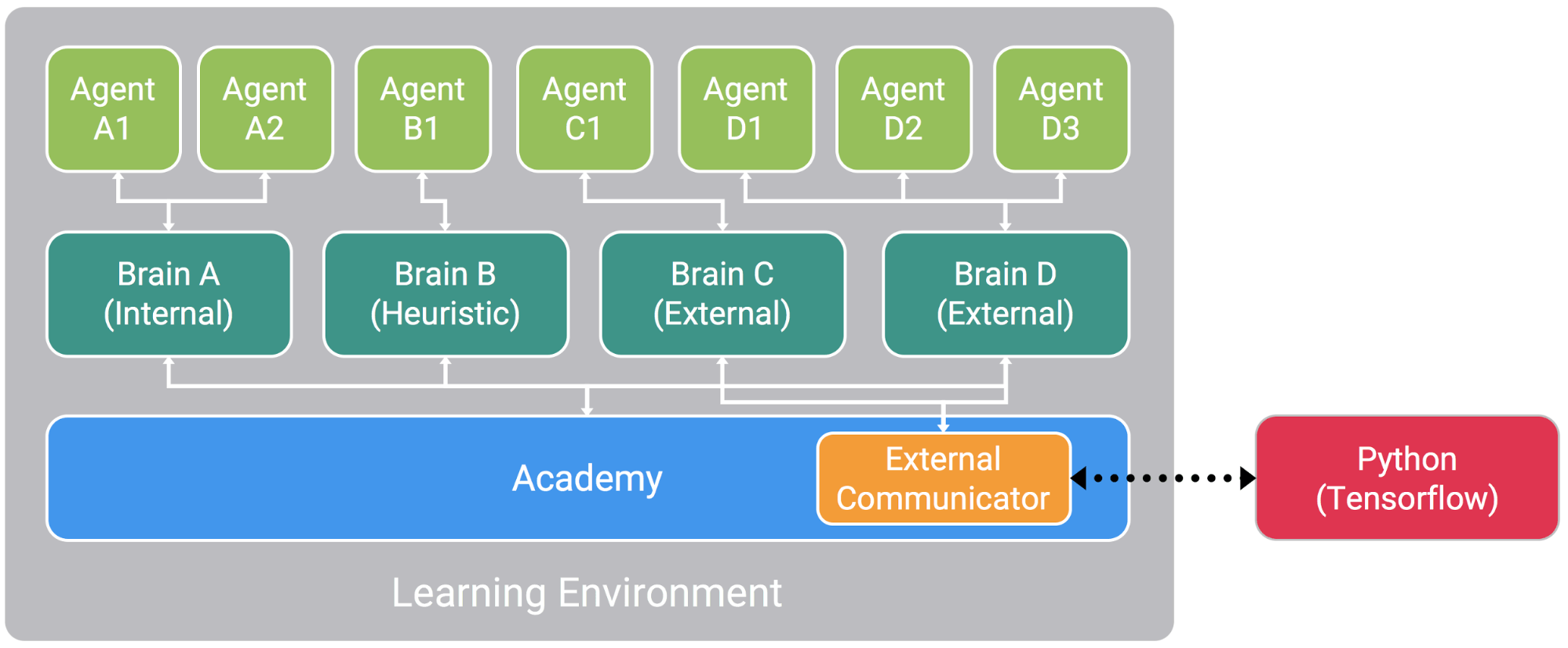
The RL Training framework in Unity. In the soccer game, I have one academy, three brains, and eight agents.
To train an ML agent in a scene, you need to define three things:
- Agent – Each agent collects observations to pass to the brain, and acts on the actions output by the brain. In the soccer world, each player is an agent. (2 have a goalie brain, 2 have a defender brain, and 4 have a striker brain).
- Brain – Each brain is a neural net, taking in observations and outputting actions. Set the brain to Internal for inference, and External for training.
- Academy – The overall training regime (and connection to Python/Tensorflow)
Separately, within the python folder, you can define a specific training regime for the scene. Use trainer_config.yaml to define hyperparameters for each brain (the PPO algorithm is selected by default). The PPO implementation is at python/unitytrainers/ppo/trainer.py, and the trained models are output to the python/models folder (this will contain the bytes file you’ll need to copy back to the Unity scene).
Soccer
Unity provides a demo soccer scene, with one goalie brain and one striker brain. The striker gets a reward when it scores a goal, and the goalie gets a penalty when the opposing team scores. Additionally, an existential penalty is put on the striker (the striker should want to score and thereby end an episode as quickly as possible). The goalie instead is rewarded for long episodes.
I changed up the demo scene a fair amount. First, I made the game 4v4 instead of 2v2, and I made the agent observations more elaborate. I also added a new brain type – Defender. The defender is equally motivated to score and to avoid being scored on.

4v4, with purely random policies. At this point, the players are running around randomly, and the goalies (dark purple for the blue team, yellow for the red team) have not yet learned they should stay near their own goals.
I removed the demo scene’s artificial restrictions that goalies and strikers could only roam in certain parts of the field. I compensated for this by giving the goalie a slight reward for staying in its own goalie box (presumably comparable to the human reward of being able to use hands there).

Looking distinctly more soccer-like. Goalies have learned to stay in their own box, unless there’s a good reason to leave. Often, the defender stays closer to its own goal, since it is penalized highly when the other team scores.
I also added a new reward type – possession. Here, everyone on a team is rewarded very slightly whenever their team touches the ball, and penalized when the other team touches it.
After a few hours of training, the game was definitely seeming more soccer-like, though the players learned to purposely bounce the ball of the walls. I’m now training with the wall taken out, the field a bit bigger, and a penalty to whichever team kicks the ball out. Initially I made the out-of-bounds penalty too big, and the agents became afraid to touch the ball at all. Now with a more balanced penalty, the training looks more promising. I’m curious to see what team behaviors might emerge after more time.
Humanoid Walking
I also focused this week on the walking humanoid (for simplicity sake, I’m calling him Ralph for the rest of this blog – I realize I’ve gotten into the habit of anthropomorphizing my models these days — I still love how amazing it is that you can wiggle the numbers in some randomized matrices and develop models that walk and play soccer).
I first modified Ralph so that his arms default to resting near his sides (the Unity scene has his arms out in a T-shape – probably because it makes balance a lot easier). I trained a policy from scratch, until he was able to successfully take a few steps. I then experimented with slightly changing the shape of Ralph’s feet. Perhaps unsurprisingly, even a small shift broke the trained policy, and he fell over at every try.

Ralph wasn’t too happy when I added a toe joint.
I decided to make a few changes at once and then retrain from scratch using PPO. To more closely mimic human walking, I added a toe joint to the model. I also changed the observation state to include the last 3 frames (joint angles and speeds at the last 3 time steps), rather than just the current frame. I speculated that having information about the recent past would help the model learn about the recent trajectories, and would be more useful than just a single snapshot. I still feed all observations directly to a densely connected neural net. In the near future, I’ll also try switching this to be an RNN.
After several hours on my laptop, Ralph did figure out a way to move to the target.

He didn’t learn to walk (on this training run), but at least it gets the job done.
I’m now completely fascinated by how easy it is to break these models. I have been thinking a lot about how humans walk, and how effortlessly we pick up a backpack or wear high heels, and we don’t have to relearn how to walk. (Well, maybe high heels do take some practice, but it’s certainly not as disastrous as changing Ralph’s shoes!)
I’m currently experimenting with adding some noise to the training process to see if I can build in more robustness. At each episode, I start the model with a very slightly different foot shape, weight distribution, and floor friction.
I’m also curious if there’s a better way to damp down all the extraneous arm movements. I’ve been penalizing the model for high hand velocities, but I’m looking to find a more systematic way to reduce energetic motions. I noticed this particularly when I tried putting Ralph in a pool of water to see if he could learn any sort of swimming motion. He soon developed very fast motions that flung his body out of the water (some sort of butterfly stroke on steroids).
In general, I’m interested in some of these things that humans do well, but which Ralph can’t do at all:
- Ability to make small modifications without needing to retrain
- Ability to walk on new and uneven surfaces
- Ability to change to running gait at a certain speed
- Instinct to expend as little energy as possible
I’m also wondering if it could be effective to split the walking model into two separate neural nets – one only for the lower body, perhaps with only limited observations about upper body velocity and center of mass. This is partly inspired by biology, since the human body creates a walking rhythm partly from a circuit that loops only to the spinal cord (and not all the way up to the brain). Read more about spinal cord driven cyclical walking rates here. Most dramatically, meet Mike, the chicken who ran around for 18 months with his head cut off
Studying other RL algorithms
Throughout the week I often found myself with long stretches while models were training.

Rather than trying my hand at swordfighting, I watched several more of the Berkeley CS 294 lectures. This is really an excellent course, and Sergey Levine presents the material in such a clear and logically ordered way.
Last week I promised a summary of specific RL algorithms, but then I found this awesome writeup. For the deepest understanding though, I’d highly recommend going straight to the Berkeley lectures. They do take some time (and mathematical fortitude), but are well worth the effort.
Upcoming
Next week I’m going to continue exploring how to make policies more robust. I’m also planning to switch back over to OpenAI’s Gym.

